昨日のmastodonサーバ停止原因と復旧手法 原因はHDD容量オーバー!?
昨日(5.23)私が運用している mastodon のサーバが停止しました。原因の究明と対策について書いていきます。
発生事象の詳細
昨日の昼頃からmastodonを運用しているさくらVPSのサーバ仮想CPU使用率が100%を超え、mastodonインスタンスであるカラスタンス(https://mdn.crows.tokyo)に接続できない状況となっておりました。
発見したのは夕方18時頃です。その時点ではログインができるもののコマンド補完などの機能が使えない状況となっていました。
swap領域が無くなっており/tmpが作れない状況であったみたいです。
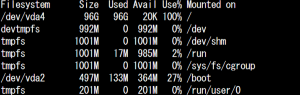
HDD領域を確認するために
du -sh
コマンドおよび
df
コマンドを使用したところHDD容量がなぜか100%となっていました。これにより常にswapファイルを移動させ続けてCPUが暴走していたようです。
復旧コマンド
docker-compose stop
を掛けたところHDD領域不足により止まらないというとんでもない状態になっていました。
nginxに関しても同様で停止できない状況でした。
そこで今回は
/tmp
フォルダおよび
/var/log
無いのデータをすべて削除して一時的な空きを作り無理矢理docker-compose stopしました。
その後
docker system prune
を実行して不要なファイルを消しました。これで十分な容量ができたため再起動します。
docker-compose up -d
systemctl start nginx
現状
上記のdocker pruneでHDD使用率は40%まで減りました。
しかしmastodonの使用データ量はかなり大きいみたいですね。今後データベースとかどうするかもう少し考える必要がありそうです。
しばらくの間はHDDがいっぱいになったらキャッシュを消してごまかしていこうと思います。
今回のHDD使用量の急増と同じタイミングでmastodon 2.4が発表されていましたが何か関係あるのでしょうか?調べる時間をとっていないので誰か詳しい方よろしくお願いします。